1. Symbolic vs. statistical machine learning
Statistical based machine learning approaches toward natural language processing (NLP), particularly large language models (LLMs), have been gratefully and deeply impacting our daily life. Our ultimate expectation on NLP, however, is a machine’s real-time capacity of both interacting with surroundings in natural language as if it was a person and reasoning in the full power of Turing machine, e.g., executing Turing-complete expressions for specific software applications. We almost have had the former but not quite yet as statistical machine learning doesn’t have a guarantee on a controllable precision, i.e., a learned program (e.g., LLM) doesn’t converges to its targeted function for a designed precisionSymbolic computing also can perform machine learning. A learned program based on symbolic computing would be gauranteed to converge, i.e., it would behave as precisely as we want by proportinally increasing sample size. Many symbolic approaches toward machine learning, such as conjunctions of boolean literals, are known benchmarks in the learning theory but they barely make an impact in learning practice due to their limited expressive power.
2. PAC learnable in Froglingo and the EP data model
Like programming language (PL), Froglingo is a symbolic and Turing-complete language system. It however has a database component, called the Enterprise-Participant (EP) data model. Although EP is not Turing-complete, it can inventory whatever the Turing machine produces and supports software applications as effectively as the Turing machine does. For example, the Turing machine can express the mathematical function f(x) = x + 1 for all integers including the infinity ∞, but in reality it can only produce a finite set of properties of f, i.e., {(0, 1), (1, 2), ..., (n, n + 1)} for a finite integer n, which is what EP can do too. EP is the most powerful database language. In the theory of computability, we say EP is semantically equivalent to the Turing machine.On the other hand, we found it is easier to use EP to construct certain applications than using currently popular technologies such Python. For example, a directed cyclic graph with edges: v1 to v2 , v2 to v1, and v2 to v3 is constructed with an EP database: D = {v1 v2 := v2; v2 v1 := v1; v2 v3 := v3}, the EP reduction language can simulate one's walks along the cyclic graph, i.e., reasons the left expressions to the right expressions: v1 v2 v3 is reducible to v3, v1 v2 v1 is reducible to v1, v2 v1 v2 ... v1 is reducible to v1, ... , and further EP's built-in operators can tell if there is a path from a vertex to another, e.g., v3 (=+ v1 is reducible to true and v1 (=+ v3 is reducible to false, as well as there is a cycle between two vertexes, e.g., v2 (=+ v1 and v1 (=+ v2 is reducible to true.
Recently, we noted that databasing in EP is a process of learning. For example, randomly selecting and constructing sample paths in EP, e.g., v1 v2 := v2; v1 v2 v1 := v1, is a learning process toward the database D because there is an generic algorithm to convert the sample inputs to a database, e.g., D' = {v1 v2 := v2; v2 v1 := v1;}, and EP is already able to conclude (predict) new information, e.g., v2 v1 is reducible to v1, and v2 v1 v2 is reducible to v2, without programming in PL. Similarly, when we express in Froglingo that "driving home" is actually meant "coming home by car", e.g., person (verB drive) home := person (verB come) home (preP by car), EP would be able to express: "Jessie drove home" when EP was told: "Jessie came home by car".
The real benefit of the EP-driven learnability is that for many applications that we cannot use PL to easily construct, we can randomly pick up a set of samples, the applications' phenomena that we know well, and represent them individually in an EP database, a machine understandable form. After a foreseeable number of samples randomly selected, the learning theory guarantees that the EP database would become an ultimate application that produces reasonably acceptable results we need.
3. Froglingo system components and user interface
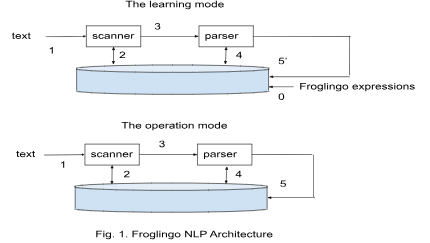
Froglingo NLP is a machine learning system. It consists of two components: 1) the core Froglingo that has a user interface accepting both the native Froglingo expressions and a natural language like English; and 2) the system's database. The system can work in either a learning (L) mode or an operation (O) mode. In the L mode, the system takes labeled sample text messages, where each message is a pair of a text and one or multiple corresponding Froglingo expressions, called templates, to guide parsing and processing the text. The system's database contains the templates entered through the L mode, and also contains learned data through the L mode and the O mode as well. The templates function as part of the learning algorithm. The learned data, through EP's reduction/reasoning system, functions as a predictor.When the system works in the learning mode, it accepts and processes the Froglingo expressions that are related to the text, where the text and the Froglingo expressions are entered through two separate areas of a user interface, and the froglingo expressions function as parsing and mapping rules (or called templates). See below for a user interface prototype with two sample text and Froglingo expression pairs:
-
[[A man with a hat walks on a street; || person (verB walk) (preP on street); person (verB wear) hat;]]
- [[John lives in manhattan; || person (verb live) (preP in location := there_is $p: [$p isA person] where $p geoLoc {=+ location and $p name == john;]]
where the special symbols [[ and ]] surround a pair and || separates a text from the corresponding Froglingo expressions.
Given a pair, the system stores the Froglingo expressions in the database first. Then, the system parses the text with built-in grammatical rules including those for breaking a complex sentence with subclauses, infinitives phrases, and/or gerund phrases into multiple simple sentences. The parsing process simultaneously references the database containing the newly added Froglingo expressions and prior knowledge to ensure the text makes sense grammatically and semantically. We assume that a text in the L mode always makes sense and the system can continue to process the structured data parsed from the text (otherwise, an error message will be given against the L mode). After a text is successfully parsed, the system will create new data. In the first example above, the system would always generate a new Froglingo data like man003 (verB walk) (preP on) street008; man003 (verB wear) hat009, where man003, street008, and hat009 represent a man, a street, and a hat respectively. For the second example, the system would create new data like man004 (verB live) (preP in manhattan) when the system doesn't find a John living in Manhattan (otherwise, the system would not create new data).
In the O mode, the system, which would have accumulated certain knowledge through the learning mode in a database, takes a text as the only input and parses it in the same way in the L model. The system in the O mode normally doesn't create new data upon a text, which largely reflects states, but validates the text. When a text like "a man walks on a street" is prompted to the system in the O mode, for example, the system that has acquired the knowledge about a man and John as discussed earlier would respond with a text like "Yes". When a text like "John lives in Boston" is prompted, the system would respond like: "No, John lives in Manhattan". The system in the O mode may create new data for certain text demanding actions, such as a person purchasing a good or moving from a location to another. Creating or not creating new data in the O mode depends on the templates that are selected to parse and map the given text. For example, a template person (verB go) (preP from) $l1: [$l1 isA location] (preP to) $l2: [$l2 isA location] := (update person geoLoc := $l2 geoLoc), where the built-in operator update enforces data update for both the O mode and L mode.
Fig. 1 gives a diagram demonstrating the similarities and differences between the L mode and the O mode. When the system scans and parses a text, it indiscriminately takes the same steps numbered 1 to 4. The system processes parsed text differently when in the L mode, as depicted as step 5', from when in the O mode, as depicted as step 5. The system may accept Froglingo expressions only in the L mode.
The more sample text are processed, the richer the NLP system will be. When the system is accumulated with certain amount of templates, additional templates may no longer needed even more sample text is needed to further enrich the templates and the predictor. At this point, we would say that the NLP system "fully understands" a natural language, and that individuals without a software development experience would be able to operate in both L and O modes, driving knowledge accumulation and giving instructions in natural language for tasks that are required to be reliably executed.